How HTTP Remembers Things
Without Breaking Statelessness

I'm a passionate backend dev
In the last article, we left HTTP in an awkward place. It forgets everything.
On purpose. Every request is treated like a stranger showing up at the door. No memory. No history. No context. And yet…
You stay logged in.
Your cart doesn’t disappear.
Websites remember who you are.
So what’s really going on? Is HTTP secretly cheating? Not exactly.
The Core Trick: HTTP Doesn’t Remember
You Do. This is the most important idea in this entire article. HTTP itself never remembers anything. It doesn’t store state. It doesn’t keep conversations.
Instead, it shifts the burden elsewhere. HTTP remembers things by making clients carry the memory. Once you see this, everything starts to click.
Statelessness Was Never About Forgetting Data
It Was About Where Memory Lives. HTTP didn’t say: “State is bad.”
It said: “State should not live inside the server.”
That distinction matters. Memory still exists.
It’s just:
Explicit
Transferable
Reconstructable
And most importantly: Not tied to a single server
Every Request Becomes a Small Self-Contained Story
Because servers don’t remember, each request must explain itself. It has to answer questions like:
Who are you?
What do you want?
Under what conditions?
That information travels with the request. This is why HTTP requests feel verbose. That verbosity is intentional.
Headers: The Quiet Workhorses
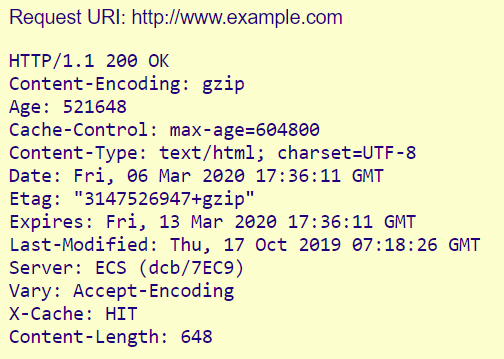
Before talking about cookies or sessions, we need to talk about headers.
Headers are not magic. They’re just structured metadata.
They let requests say:
“Here’s what I support”
“Here’s who I might be”
“Here’s how you should treat this”
Headers don’t store state. They carry state.
Big difference.
Cookies: Memory With a Return Address
Now let’s talk about the thing everyone knows and half-understands.
Cookies.
Here’s the key idea:
The server gives the client a small piece of data
The client sends it back with every future request
The server still remembers nothing. The client becomes the messenger.
From HTTP’s point of view: “Every request just happens to include some extra data.”
No rule is broken.
Sessions Are Not an HTTP Feature
This is where confusion usually starts. Sessions feel like HTTP remembers you.
It doesn’t. What actually happens:
The server gives you a session identifier
You send it back on every request
The server looks things up using that identifier
The memory lives outside HTTP, usually in:
Databases
Caches
In-memory stores
HTTP just delivers the identifier.
Tokens (JWT : JSON Web Tokens) : Pushing Memory Even Further Out
Sessions are great, but they have one flaw: the server still has to "look something up" in a database. If you have 10 million users, that’s a lot of lookups.
JWTs are the modern solution. Think of a JWT as a Passport. A passport doesn't just have an ID number; it has your name, your birthday, and your photo printed right on it. Most importantly, it has an official seal from the government.
When you show a JWT to a server:
The server doesn't look you up in a database.
It just checks the "Digital Seal" (the signature).
If the seal is valid, the server trusts the info printed on the token (like
user: "John") immediately.
This is the ultimate stateless win. The server remembers who you are without ever having to open a database.
Why This Scales So Well
Because memory isn’t tied to a server:
Requests can hit any machine
Servers can come and go
Load balancers don’t care
Failures don’t corrupt conversations
This is why modern systems survive traffic spikes and partial outages. Statelessness plus externalized memory is a powerful combination.
The Pattern You Should Notice
Let’s zoom out.
HTTP doesn’t solve state. It outsources it. And it enforces a rule: “If state exists, it must be explicit.” No hidden server memory. No invisible dependencies.
This makes systems:
Easier to debug
Easier to scale
Easier to reason about
The Tradeoff (Because There’s Always One)
Nothing here is free. This approach adds:
More data per request
More coordination
More responsibility on clients
But the alternative is worse: fragile servers that fall apart under scale. HTTP chooses boring reliability over clever shortcuts.
Why This Matters for Backend Engineers
If you don’t understand this:
Auth feels magical
Sessions feel fragile
Load balancing feels mysterious
If you do understand this:
You design cleaner APIs
You know where state should live
You stop fighting HTTP’s nature
You start working with the protocol instead of against it.
So far, we’ve covered:
How data moves
How it’s delivered
How applications talk
How memory is handled
One big piece still remains.
What Comes Next
Now that we understand how HTTP remembers, the next question is: “How do we design APIs that respect these rules?” That’s where semantics enter the picture.
➡️ Next article:
HTTP Methods, Status Codes, and Meaning
This article is part of the Thinking in Backend series, where we learn backend engineering by focusing on how systems think, not just how code runs.




